Be sure to check out my Scripting4Crypto initiative. It’s a fun way to get into using cryptocurrencies all while getting your PowerShell needs met.
I was recently asked if there was a way to get a list of duplicate document names within a project. Reason for the question was that after running a Scan References and Link Sets, some of their design files were referencing the wrong document(s).
The way the Scan References process works, as far as I know, is that the specified folders will be scanned for a document matching the name of the reference document obtained from the design file header. Once a match is found, it moves on the next reference. If you have multiple documents with the same name, the first one found is the one used. If you were not aware of the duplicate document names, you wouldn’t know to use the priority and proximity options within the Scan Reference and Link Sets tool, which apparently can cause some issues. Hopefully, this makes sense.
So, how do we get a report of the duplicate document names?
We will use the following cmdlets provided with the PWPS_DAB module to get all documents within a project, determine which ones are duplicates, and output the results to an Excel workbook. I would recommend looking at the help for each cmdlet to familiarize yourself with each.
- Get-PWDocumentsBySearch
- Convert-ObjectArrayToDatatable
- New-XLSXWorkbook
This solution was developed using PWPS_DAB version 1.10.2.0. Also, this is not the only way to accomplish this, just what I have come up with. So, if you have another way of getting duplicate document names, please share.
Get All Documents in a Project
First thing we need to do is get a list of all of the documents within the specified ProjectWise Project. For this we will use the Get-PWDocumentsBySearch. An array of ProjectWise Document Objects will be returned and populate the $pwDocuments variable.
# Project Folder to search for documents. $PWFolder = 'PowerShell\PowerShell_Test' # Get Documents to check for duplicates. # I chose to use a FolderPath. You could also use the SearchName or FolderID. <# DO NOT USE the -GetAttributes (Using this will cause the search to take much longer to complete and is not necessary at this point.) #> $pwDocuments = Get-PWDocumentsBySearch -FolderPath $PWFolder
The following image shows the number of documents and the names. Obviously, this is a very simple example, but the concept is really what I am trying to convey.

Get List of Duplicate Documents
Next, we will create two arraylists.
# Temporary array to help facilitate finding duplicate documents. $pwDocuments_Temp = New-Object System.Collections.ArrayList # Array to store duplicate document names. $pwDocuments_DuplicateNames = New-Object System.Collections.ArrayList
We will loop through all documents in the $pwDocuments variable, and add document names to the $pwDocuments_Temp arraylist. If a document already exists in that arraylist, the document name will be added to the $pwDocuments_DuplicateNames arraylist. At the end of processing all documents, the $pwDocuments_DuplicateNames arraylist will contain ONLY the duplicate document names. At this point, we will no longer need the $pwDocuments_Temp arraylist and can remove the variable.
# Loop through all documents and find any duplicate document names. foreach ($pwDocument in $pwDocuments) { if( -not ($pwDocuments_Temp.Contains($pwDocument.Name))) { $pwDocuments_Temp.Add($pwDocument.Name) | Out-Null } else { $pwDocuments_DuplicateNames.Add($pwDocument.Name) | Out-Null } } # end foreach ($pwDocument... # Remove the $pwDocuments_Temp variable. Remove-Variable pwDocuments_Temp
Now we will create a datatable by extracting out of the $pwDocuments, ONLY the document objects which match the duplicate document names, and using the Convert-ObjectArrayToDataTable cmdlet to convert the ProjectWise Document Objects to a datatable.
# Convert PWDocuments to a datatable for ability to use the .Select method. $dtDuplicates = Convert-ObjectArrayToDataTable -InputObjectArray ($pwDocuments | Where-Object Name -In $pwDocuments_DuplicateNames)
We will need to create another datatable to store the final document information to be exported. This will only include the document name and the full path to the document.
# Create new datatable to be exported to Excel. $dt = New-Object System.Data.DataTable ('Duplicates') $dt.Columns.Add("DocumentName") | Out-Null $dt.Columns.Add("FullPath") | Out-Null
Next we will loop through each of the documents within the $pwDocuments_DuplicateNames variable, select the corresponding document objects from the $dtDuplicates datatable, get the full path, and add the document name and fullpath to the $dt datatable.
We will use the .Select method to get only the data needed from the $dtDuplicates datatable. Then we will use the Get-PWDocumentsBySearch with the -GetAttributes option to get the full path to the document. We are saving a lot of time by only using the -GetAttributes switch parameter on the duplicate documents and NOT on all documents in the project. I wrapped all of this in an if statement which determines if there are any duplicate documents to report on. If not, why continue, right.
if($pwDocuments_DuplicateNames.Count -gt 0) { # Convert PWDocuments to a datatable for ability to use the .Select method. $dtDuplicates = Convert-ObjectArrayToDataTable -InputObjectArray ($pwDocuments | Where-Object Name -In $pwDocuments_DuplicateNames) # Create new datatable to be exported to Excel. $dt = New-Object System.Data.DataTable ('Duplicates') $dt.Columns.Add("DocumentName") | Out-Null $dt.Columns.Add("FullPath") | Out-Null <# Loop through each duplicate document name and populate new datatable With the document name and fullpath. #> foreach ($duplicate in $pwDocuments_DuplicateNames) { $temp = $dtDuplicates.Select("Name = '$duplicate'") foreach ($item in $temp) { $dr = $dt.NewRow() $dr.DocumentName = $item.Name # Get fullpath for current document ($item). $Splat = @{ FolderID = $item.ProjectID DocumentName = $item.Name } $pwDoc = Get-PWDocumentsBySearch @Splat -GetAttributes -JustThisFolder $dr.FullPath = $pwDoc.FullPath $dt.Rows.Add($dr) } } # end foreach ($duplicate... } # end if($pwDocuments_DuplicateNames.Count...
Finally, we export the $dt datatable, which only contains the document name and full path for all duplicate documents to an Excel workbook. Again, we will only export if duplicate documents were found.
# Output file name. $OutputFile = 'd:\temp\export\DuplicateDocuments.xlsx' if($dt.Rows.Count -gt 0) { # Export datatable to Excel workbook. New-XLSXWorkbook -InputTables $dt -OutputFileName $OutputFile }
The following shows the contents of the output file.
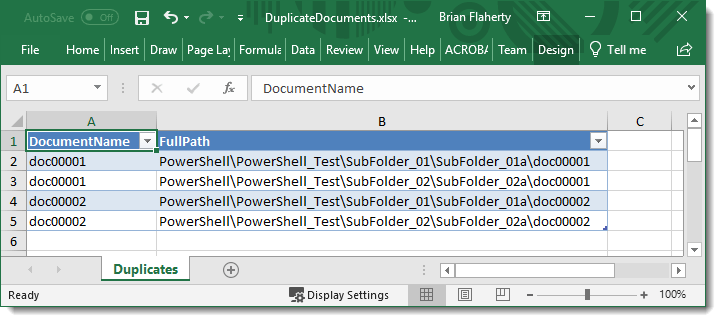
Here is link to the complete script. FindDuplicateDocumentsWithinProject
Experiment with it and have fun.
Hopefully, you find this useful. Please let me know if you have any questions or comments. If you like this post, please click the Like button at the bottom of the page.
